
BitNet: Microsofts AI Revolution Shows Why Precision May be Overrated
And why Efficiency isn’t a post-processing step — it’s a design decision.


Abstract
Microsoft BitNet is the first transformer trained from scratch using only three possible weight values: −1, 0, and +1. That translates to 1.58 bits per parameter — and results in a 2-billion parameter model that runs in under 1 GB of RAM, even on a CPU.
A few months ago, this would’ve sounded like a gimmick. But now that the model is open, usable, and GPU-compatible (albeit shakily), BitNet forces a deeper question: Have we confused bit precision with actual intelligence? And more importantly: if BitNet works — what exactly have we been wasting our compute on?
1. What BitNet Actually Does
BitNet b1.58 2B is a language model trained on 4 trillion tokens. But unlike most of today’s quantized models, BitNet doesn’t take a finished float16 model and compress it downward. It starts at the bottom — from scratch — using only ternary weights: −1, 0, or +1.
This isn't a technicality. BitNet is not "compressed." It's born small.
Because you can’t just round high-precision weights and expect intelligence to survive. At 1.58 bits, information must be constructed explicitly, not approximated after the fact. That design decision — full ternary training — changes everything: optimization, memory layout, inference engine, and even how we think about structure in LLMs.
And the results are nontrivial:
Inference RAM: ~400 MB
Tokens/sec (CPU): 6–8, no GPU
License: MIT, weights included
Hardware needed: MacBook, Raspberry Pi, or literally any modern CPU
This is not a research toy. This is a functioning LLM.
2. Context: LLaMA 3.2 and the 4-Bit Ceiling
To appreciate BitNet, compare it to the most widely used “lightweight” models in 2025: Meta’s LLaMA 3.2 in its 3B configuration. At 4-bit quantization, it represents the practical compression limit of mainstream LLMs — running reasonably well, with tolerable quality loss, and modest compute needs.
But even in its tightest form, LLaMA 3.2 3B still demands:
~2.0 GB on disk
2.5–3.0 GB RAM during inference
Usually a GPU, especially for large context
And a restrictive Meta license
Compared to BitNet, that’s not small. That’s just smaller than the monsters.
What BitNet demonstrates is that “small” is a relative term — and that LLaMA’s lower limit still isn’t particularly low.
3. Benchmarks: Lean, But Not Limp
BitNet doesn’t just run. It performs — surprisingly well.
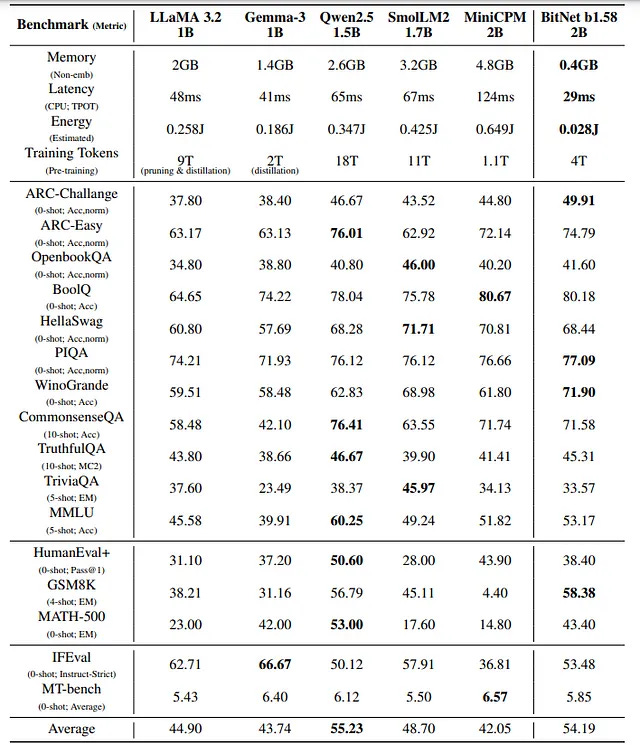
In direct comparison with other open models in the 1–2B range (LLaMA 3.2 1B, Gemma-3, Qwen 1.5B, SmolLM2, MiniCPM), BitNet holds its own across a wide spread of tasks. Despite having the lowest memory footprint in the table — just 0.4 GB vs. 2–4.8 GB — and using 10–20× less energy than most others, its average performance ranks second overall, behind only Qwen-1.5B, a model trained on nearly 5× more data.
Its inference latency is also telling: 29 ms, beating every other model in the lineup. For a model running on CPU, that’s not just good — it’s structurally disruptive.
This isn’t “good enough” performance. It’s proof that low-bit architectures aren’t just viable — they’re competitive.
4. GPU Support: The Fragile Boost
In May 2025, Microsoft added experimental GPU support to bitnet.cpp, enabling CUDA (RTX 30/40 series) and Metal (Apple Silicon).
Early benchmarks show BitNet running 1.7–2.3× faster on GPU vs CPU. But these wins come with caveats:
On longer prompts (>800 tokens), generation can collapse into infinite loops (GitHub Issue #285).
Compatibility is limited — no ROCm, no mobile GPU support.
BitNet’s GPU inference still relies on lookup-table hacks, not native tensor ops.
In short: GPU support works — barely. It’s a preview, not a deployment target.
5. Why BitNet Matters
BitNet doesn’t outperform GPT‑4o. It doesn’t claim to. But that’s not the point.
Its importance lies elsewhere:
It challenges the assumed link between precision and intelligence.
It proves that structure can emerge from 1.58 bits per weight.
It shifts LLM engineering from “bigger” to “smarter.”
For offline tools, edge devices, embedded systems, or sovereign compute contexts, BitNet isn't a compromise — it’s a candidate.
A language model that runs on CPU, fits in RAM, and doesn’t phone home?
That’s not a lab curiosity. That’s a design alternative.
6. The Catch: No Shortcuts Allowed
BitNet is elegant, but unforgiving.
Fine-tuning is possible — LoRA adapters can be layered on top — but they reintroduce FP16 elements, especially in scale tensors and optimiser state. And there’s no native LoRA path in bitnet.cpp yet. Tuning remains a compromise.
But the bigger catch is this:
BitNet models can’t be quantized into existence.
You can’t take a LLaMA or Mistral checkpoint and squeeze it into 1.58-bit form. The ternary weights must be learned from scratch — weight by weight, token by token, under full gradient pressure.
Why? Because rounding FP16 weights to –1, 0, or +1 doesn’t preserve structure. It obliterates it. At this level of precision, learning isn’t just optimization — it’s architecture.
So unlike most “small” models in 2025, BitNet isn’t a compression artifact. It’s a full training path. And that’s both its strength and its cost.
7. The Illusion of Precision
BitNet does something more important than save memory. It punctures the myth that precision is inherently valuable.
We’ve come to equate intelligence with floating point density — 16 bits good, 8 bits cutting-edge, 4 bits experimental. BitNet says: none of that matters, if your structure is smart enough.
And it shows — with running code — that inference can be fast, memory-light, and power-efficient, without being dumb.
The LLM landscape won’t pivot to ternary overnight. But BitNet has already planted the seed:
Maybe we didn’t need 32-bit transformers.
Maybe we just didn’t know how to build better ones.