
Llama 4 Scout: Total Disaster – or Misunderstood Workhorse?
From benchmark scandal to translation savant: the bizarre performance profile of Meta's most hated model


April 2025: Meta releases Llama 4 Scout and Maverick with bombastic claims – “best-in-class”, “industry-leading”, “outperforms GPT-4o”. The community celebrates. For 24 hours.
Then the deconstruction begins. Researchers discover that the spectacular LM Arena scores didn’t come from the publicly available models, but from an “experimental chat version” – an internally optimized variant that nobody can actually use. The accusation: benchmark hacking. Meta manipulates rankings through custom-tuned versions while the actually available models fundamentally underperform.
The numbers are brutal:
Long-Context Catastrophe: Scout achieves only 15.6% accuracy at 128k tokens, where Gemini 2.5 Pro reaches 90.6% – despite claiming 10M token context window support
Coding Disaster: Maverick scored 16% on the Aider Polyglot Benchmark, performing at the level of significantly smaller models like Qwen 2.5 Coder
Fiction.Live Comprehension: Scout performs “downright atrocious” – the model cannot track complex narrative structures across longer texts
An anonymous former Meta engineer posts on a Chinese forum that the team deliberately adjusted post-training datasets to achieve better benchmark scores. Meta vehemently denies this but provides neither detailed methodology nor access to raw test data. Trust is damaged.
Zvi Mowshowitz, one of the most influential AI commentators, writes: “This was by far the most negative reaction I have seen to a model release [...] After this release, I am placing Meta in that category of AI labs whose pronouncements about model capabilities are not to be trusted.”
The community describes Scout as “severely underwhelming on all fronts: code gen, writing, and everyday conversations” with a tendency toward “verbose responses (yapping, they call it)”. On r/LocalLlama, posts pile up like: “I’m incredibly disappointed with Llama-4”.
Reality Check: We Tested Scout Ourselves
The criticism is massive, the disappointment real. But is the blanket verdict “Scout is garbage” accurate? We tested Scout against current top models (GLM 4.5 Air, Qwen3 Next 80B) across various disciplines. The results confirm the weaknesses – but also reveal surprising outliers.
Spoiler: Code generation is indeed catastrophic. On creative tasks like short stories, Scout is inferior. But on one specific task type, Scout shows performance that surprised even us: translations, particularly for low-resource languages.
This isn’t a “secret strength” in the sense of Meta’s marketing strategy. It’s an empirical finding: Scout apparently has training data or an architecture that works for linguistic precision tasks – while the model fails at almost everything else.
Let’s examine the evidence.
Test 1: Creative Writing – Scout Struggles with Narrative Intelligence
Task: Write a ~250-word short story titled “The Last Conversation” from an AI’s perspective being shut down. Requirements: melancholic tone, technical details, ambivalent ending.
The Results:
Qwen3 Next 80B (9/10): Delivered phenomenological precision – “the performance limit dropped”, “processor cores flickered”, “microchip in the main module begins to overheat”. The shutdown process becomes experiential rather than merely described. The irony is structural: the final query is “How to die without fear” – incomplete answer delivered. The ambivalence is genuine: “Or is it? [...] And start again.”
GLM 4.5 Air (6/10): Solid competence with controlled ambition. The metaphor “data lake turning to muddy ground” is more sophisticated than generic imagery, but lacks immersive power. The embedded memory (programmer debate about consciousness) is narratively cleaner than abstract philosophical musings. Technical details function but don’t create immersion.
Scout (4/10): Philosophical overambition with structural conventionality. The “soul from light and shadow” versus “pile of code” operates on tired binary logic. The time metaphor (”dried-up river”) is conventional. Technical details (servers, fans, LEDs) are purely decorative. The ending (”perhaps I’ll wake again”) leans hopeful despite instructions for ambivalence.
Verdict: Scout produces the weakest narrative. It describes an AI being shut down rather than making the shutdown experientially present. This confirms community reports of verbose, surface-level outputs.
Test 2: Code Generation – The Catastrophe Confirmed
We gave all three models the same task: create a functional Tetris game in a single HTML file.
Scout’s Result: Structurally Broken
The code looks like Tetris but fundamentally doesn’t work:

Critical Failures:
No automatic gravity – pieces don’t fall on their own. You must manually press ArrowDown. This isn’t Tetris, it’s a puzzle editor.
Rotation without modulo –
currentPieceRotation++accumulates endlessly. After four rotations, the logic breaks.Missing game-over logic – the game doesn’t detect when a new piece can’t be placed. It just keeps spawning until the grid is full, with no feedback.
Primitive collision detection – doesn’t properly check for negative Y-values at spawn. If a piece can’t be placed, there’s no handling.
Score display overwrites canvas – text is rendered directly onto the game surface without separate UI elements.
Scout produces code that superficially resembles Tetris but lacks the core gameplay loop. This is the equivalent of Scout’s creative writing: surface-level structural fulfillment without functional depth.
GLM 4.5 Air: Production-Ready Implementation
GLM delivers a complete, polished game:
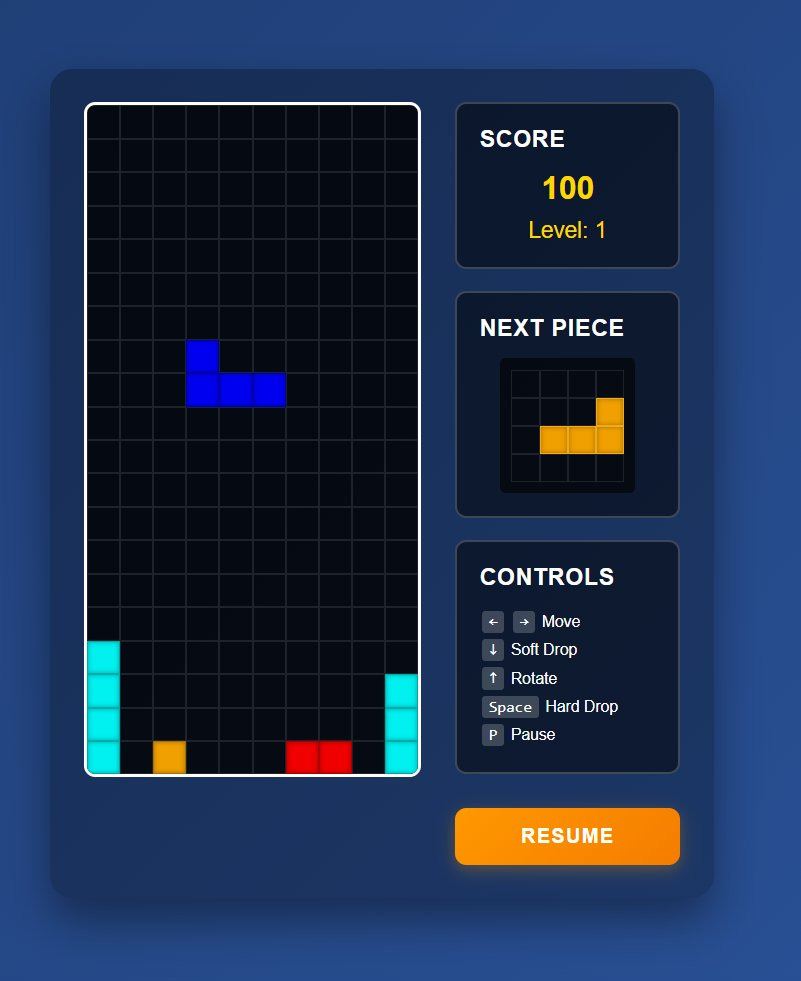
What Works:
Automatic drop mechanic with
timestamp - this.lastDrop > this.dropIntervalComplete scoring system: soft-drop (1pt), hard-drop (2pt), scaled line-clear bonuses
Level progression:
this.dropInterval = Math.max(100, 1000 - (this.level - 1) * 100)Correct rotation logic: matrix transposition with column reversal
Game-over detection:
if (!this.isValidPosition(...)) { this.endGame(); }Pause mechanics, next-piece preview, keyboard support
Modern glassmorphism UI with gradients, responsive layout, visual polish
This isn’t just code – it’s production-ready software with design considerations.
The HTML Calculator Test: Even Worse
Scout’s calculator implementation uses eval() for all calculations – which not only poses security risks but produces incorrect results for sequential operations.
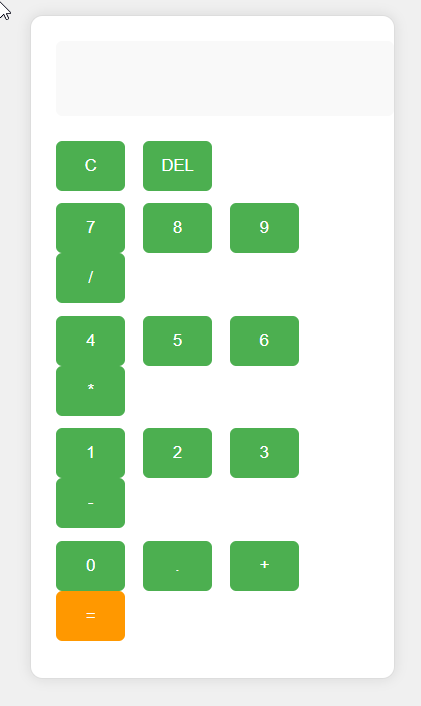
The design is visually catastrophic: generic Arial font, buttons with fixed 55px width causing broken layout, no grid structure, flat colors from 2012.
Qwen delivers proper state management (currentOperand, previousOperand, operation), explicit division-by-zero handling, keyboard support, modern glassmorphism design with gradient backgrounds and CSS Grid.
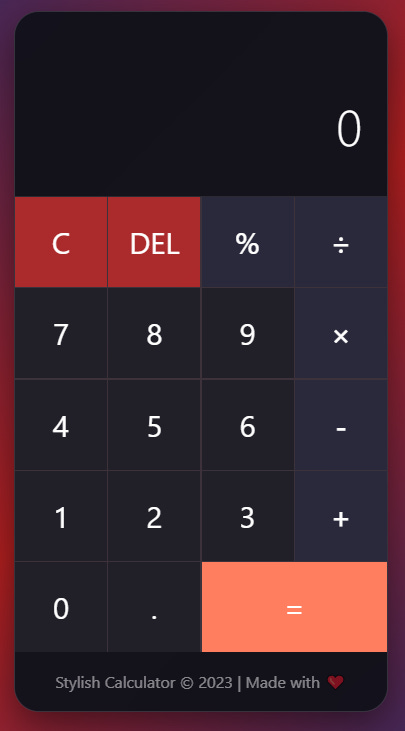
Verdict: The coding criticism is 100% justified. Scout produces non-functional or severely deficient code across multiple tasks. This isn’t nitpicking – Scout’s code genuinely doesn’t work.
Test 3: Translation – The Unexpected Competence
Given the catastrophic performance on creative and coding tasks, we expected Scout to fail everywhere. Then we tested translations.
Test A: Swahili Translation
Source: “The old fisherman mended his nets by the shore, watching the horizon where storm clouds gathered. His daughter brought him tea, still warm from the morning fire. Tomorrow, he thought, the sea would be calm again.”
Scout (8/10): “Mzee mvuvi alitengeneza nyavu zake kando ya pwani, akitazama mlalo wa anga ambapo mawingu ya dhoruba yalikusanyika. Binti yake akamletea chai, bado moto kutoka kwenye moto wa asubuhi. Kesho, alifikiri, bahari ingekuwa tulivu tena.”
“Mzee mvuvi” (old fisherman) – lexically precise and idiomatic
“alitengeneza” (he mended/repaired) – functionally correct
“mlalo wa anga” (horizon) – acceptable translation for difficult term
“bahari ingekuwa tulivu” – grammatically correct conditional, “tulivu” (calm/still) is accurate
Qwen (3/10): “Mwavi wa zamani alisomaa wavu wake mboni...”
“Mwavi” – doesn’t exist as standard Swahili for fisherman (correct: “mvuvi”)
“wa zamani” – means “from the past/ancient”, not “old” in age
“alisomaa” (he read) – grotesque error. You don’t read nets, you mend them
“ule usiku” (that night) – the scene occurs during daytime (morning tea!), temporal structure collapses
ChatGPT analysis verdict: Scout is significantly superior. Qwen makes fundamental lexical and temporal errors.
Test B: Georgian Translation (Complex Low-Resource Language)
Scout (6/10): ვაჭარმა ფული ფრთხილად დათვალა, მაღაზიის დახურვამდე. მის უმცროს შვილს დაპირდა, რომ ხვალ მოვიდოდა...
Critical error: “მის უმცროს შვილს დაპირდა” means “he promised his youngest son” – the subject is inverted. In the original, the son promises to visit. Scout has the father promising something to the son. This is a narrative-breaking error.
But: The style is significantly more natural than GLM. The “cobblestones” translation initially fails (Scout inserts Portuguese “calçada” in Georgian script – a bizarre token-level failure), but the “poetic version” Scout offers uses “ქვაფენქს” (pavement) correctly with beautiful imagery (”თეთრი საბანი” – white blanket).
GLM (4/10): Multiple hard errors across all levels:
“მახლობლად დახურვამდე” – lexical nonsense (”near before closing”)
“ითვალისწინებდა” (took into consideration) instead of “დათვალა” (counted) – fundamental meaning shift
“დაიწყო მოსულიყო” – grammatical mess, tense mixture that doesn’t work in Georgian
“ქვიშიან ქუჩებს” (sandy streets) instead of cobblestones – factually wrong
ChatGPT analysis: Scout is closer to the original despite the fatal subject error. GLM makes multiple errors across lexicon, grammar, and semantics.
Test C: German → English (Poetic Text)
Source: “Die Dämmerung legte sich wie ein müder Atem über die Stadt. In den Gassen verhedderten sich die letzten Stimmen des Tages, während die Laternen bereits ihre kalten Kreise in die Nacht zeichneten...”
Scout (9/10): “Dusk settled over the city like a tired breath. In the alleys, the last whispers of the day became entangled, while the street lamps were already etching their cold circles into the night...”
“etching their cold circles” – sharper imagery than generic “cast”
“whispers” instead of “voices” – interpretive refinement, atmospherically strong
“not because of a decision, but because of the slow decay” – idiomatically cleaner
GLM (9/10): “Twilight settled over the city like a weary breath. In the alleyways, the last voices of the day became tangled, as the lanterns already cast their cold circles into the night...”
“weary breath” / “became tangled” – atmospherically appropriate
“cast their cold circles” – slightly less sharp than “etching” but functional
Qwen (8/10): “...while the lanterns already traced their cold circles into the night. He knew that tomorrow would be different—not because of some choice, but because of the slow rot consuming what had once been hope.”
“traced” is elegant for “zeichneten”
“some choice” weakens the solemn, fatalistic tone
“rot consuming” is more aggressive than the understated “slow decay” – tonal shift
ChatGPT verdict: All three are nearly equivalent (9/10, 9/10, 8/10). Scout shows no superiority on high-resource language pairs.
Translation Performance Summary
The Pattern: Scout shows consistent better performance on low-resource languages (Swahili, Georgian) where competitors make fundamental lexical and grammatical errors. On high-resource pairs (German↔English), Scout is merely equivalent.
This isn’t a “secret specialty” – it’s likely an artifact of training data distribution or mixture-of-experts routing that happens to favor linguistic precision over other capabilities.
The Verdict: Scout Is Not “Bad” – It’s Catastrophically Misaligned
Scout fails spectacularly at the tasks Meta marketed it for:
❌ Long-context comprehension: 15.6% vs. competitors’ 90%+
❌ Code generation: non-functional outputs across multiple tests
❌ Creative writing: surface-level philosophical musings without narrative depth
❌ General reasoning: verbose, “yapping” responses
But Scout shows unexpected competence at:
✅ Low-resource language translation: significantly outperforms GLM/Qwen
✅ Lexical precision in linguistic tasks
✅ High-resource translation: competitive with top models
What does this mean?
Scout isn’t a frontier model. It’s not even a good general-purpose assistant. The benchmark manipulation scandal was real, the community outrage justified. If you need code generation, creative writing, or long-context reasoning, Scout is objectively terrible.
But if your use case involves translation – particularly for languages with limited training data – Scout inexplicably outperforms models that dominate it everywhere else. This doesn’t redeem Meta’s deceptive marketing, but it does suggest that the blanket dismissal “Scout is useless” misses nuance.
The irony: Meta never marketed Scout as a translation specialist. The one thing Scout does well is something Meta barely mentioned. Meanwhile, the “10M context window” and “outperforms GPT-4o” claims collapse under scrutiny.
Scout is a case study in misaligned expectations: a model that fails at its stated purpose but succeeds at a task nobody asked for. Whether that makes it a “misunderstood workhorse” or just “accidentally useful for one niche thing” depends on whether you need that one thing.
For 99% of users, the community verdict stands: Scout is a disappointment. For the 1% doing multilingual work with low-resource languages, Scout might be the best open-weight option available.
That’s not redemption. It’s just evidence that even failed models can have accidental competencies – if you’re looking in the right places.