
Run Local AI with UI in Minutes – No Setup, No Coding
A minimal guide to running offline AI with zero setup using Llamafile on Windows.


What is Llamafile?
Llamafile is a new way to run large language models (LLMs) entirely on your local machine. Instead of dealing with complex setups, Python environments, or cloud services, Llamafile packages everything into a single executable file. The model and the code needed to run it are bundled together.
This means:
No installation
No internet connection required during runtime
No accounts, no telemetry
Just download, rename, and run.
Step-by-Step Guide (Windows)
1. Download the Model
Download a prepackaged model file from Hugging Face:
Save it to a known location, e.g. your Downloads folder.
2. Rename the File
Once downloaded, rename the file from:
google_gemma-3-4b-it-Q6_K.llamafileto:
gemma.exeWindows may warn you about changing the file extension. Click "Yes" to confirm.
3. Launch via Command Line
Open the folder where you saved
gemma.exeClick into the address bar of the File Explorer window (where the path is shown)
Remove what you see, type
cmdand press EnterIn the command prompt window that appears, run:
gemma.exe --server --v2This starts the model and a local web server.
4. Open the Web Interface
Open this address in your browser:
http://localhost:8080
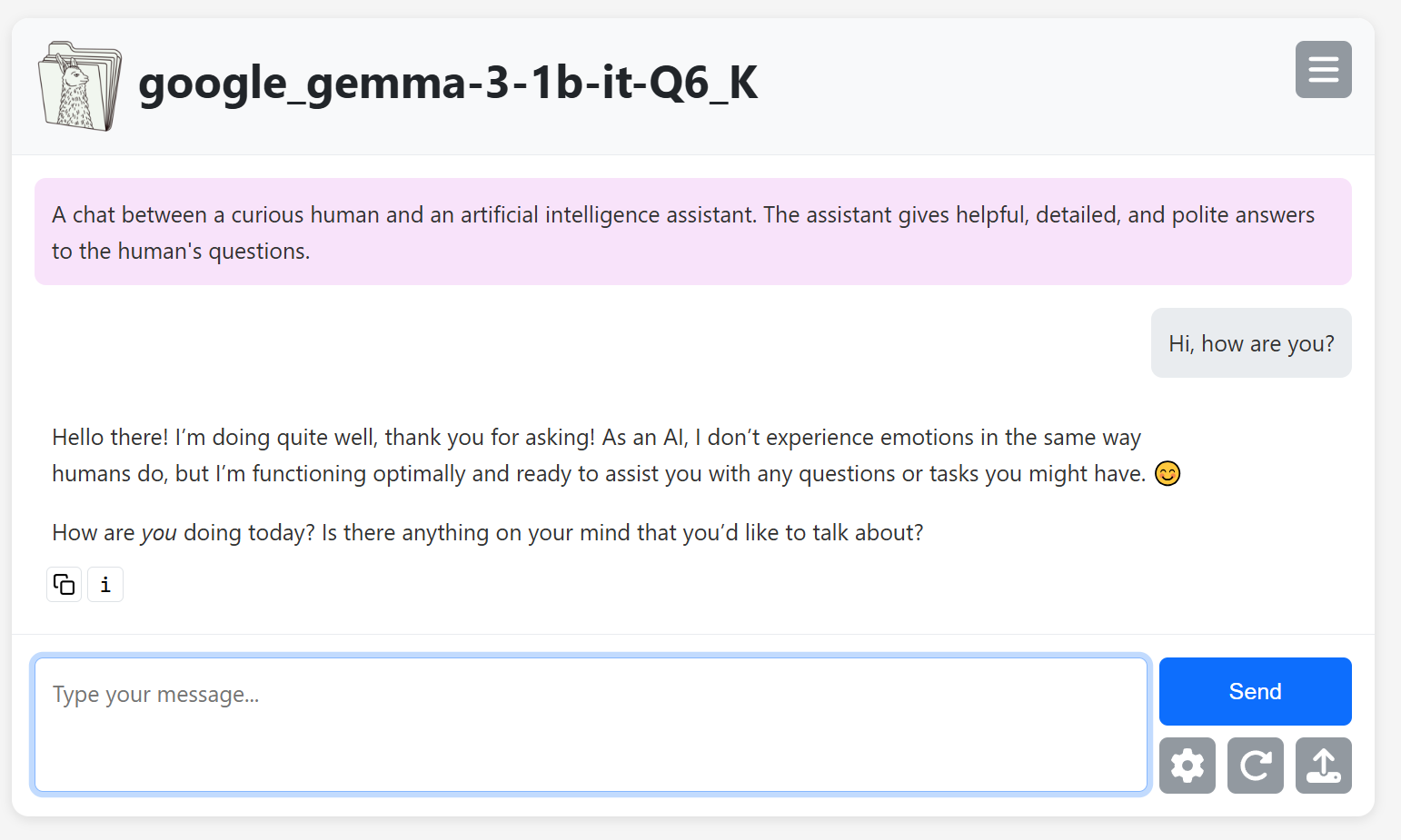
You can now chat with your AI assistant directly in your browser, running entirely on your own machine.
After a few seconds, the terminal will show something like:
Summary
Llamafile lets you run full AI models with zero setup.
No cloud, no APIs, no dependencies.
You’re in full control of the software and your data.
Optional: Use Other Models
You can repeat the same process with any .llamafile file from https://github.com/Mozilla-Ocho/llamafile. Simply rename it to .exe and run it with the same --server --v2 flags.
This method is compatible with models like Mistral, LLaVA, Code models, and more.