
The Hidden Reasoning Hack: Turning Standard Models into Thinking Machines
How we accidentally discovered that some standard LLMs can think like reasoning models - with nothing but a prompt


We stumbled onto something weird last week. And we’re not entirely sure anyone else has noticed it yet.
You know how there's been this whole arms race around "reasoning models" — starting with OpenAI's o1 as one of the pioneers, now evolved into GPT-5.2 Thinking, Google's Gemini 3 Deep Think, DeepSeek R1? Models that explicitly show their chain-of-thought before answering? The ones that pause, deliberate, and write out their reasoning process in <think> tags before giving you an answer?
Well, here's the thing: You might've had one all along - in a model you never suspected.
Not a specialized reasoning model. Just a regular Gemma 3 or Llama 3.1. And with the right system prompt, they suddenly... think.
Let us show you what we mean.
The Accidental Discovery
We were experimenting with NousResearch’s Hermes 4.3, a hybrid reasoning model that lets you toggle CoT mode via system prompt. They provide this instruction:
You are a deep thinking AI, you may use extremely long chains of thought to deeply consider the problem and deliberate with yourself via systematic reasoning processes to help come to a correct solution prior to answering. You should enclose your thoughts and internal monologue inside <think> </think> tags, and then provide your solution or response to the problem.
Standard stuff for a reasoning model. But then we had a thought: What if we tried this on a model that was never trained for reasoning?
So we tested it on Gemma 3. A completely standard, non-reasoning model.
It worked.
Not just “kind of worked.” It fundamentally changed how the model operated.
Show, Don’t Tell: A Side-by-Side Comparison
Let us give you a concrete example. We gave both versions (with and without the reasoning prompt) this structurally complex creative writing task:
The Prompt:
“Write a story about a neuroscientist who develops early-onset dementia and begins experiencing temporal discontinuities in her perception. As her condition progresses, she becomes convinced that her fragmented memories aren’t degrading but are instead accessing parallel timelines of her life - versions where she made different choices at critical junctures.
The narrative should interweave at least three distinct timeline threads:
Her present deterioration and her family’s attempts to care for her
A timeline where she pursued her first love instead of her career
A timeline where she never left her hometown
The story must maintain internal logical consistency for each timeline while deliberately blurring the boundaries between ‘actual memory,’ ‘false memory,’ and ‘parallel reality’ - leaving ambiguous whether her theory has merit or is purely symptomatic. The resolution should neither confirm nor deny the parallel timeline hypothesis definitively.”
This is demanding: multiple causal chains, distinct characterizations across timelines, epistemological ambiguity without collapsing into incoherence.
Without Reasoning (Standard Gemma 3):
The model immediately started writing. No planning phase. Here’s how it opened:
Dr. Aris Thorne stared at the teacup in her hand. Steam rose from it, or was it? She couldn’t remember making tea. Her daughter Lena appeared beside her. “Mom, you’ve been holding that cup for twenty minutes.”
Aris blinked. Twenty minutes? It felt like seconds. Or hours. Time was... slippery lately.
She remembered Daniel. Or did she? The workshop, the smell of wood. But Daniel was her colleague, wasn’t he? No, that was David. Or was David from the town?
The output had:
Timeline confusion: Jumps between timelines felt random rather than deliberately disorienting - the reader couldn’t tell if this was intentional ambiguity or authorial confusion
Inconsistent tone: Each timeline didn’t maintain distinct emotional signatures - the “workshop” memory had the same clinical tone as the “present” scenes
Premature resolution: The ending explicitly confirmed she was experiencing dementia hallucinations, destroying the required ambiguity
Shallow symbolism: Mentioned “slippery time” but never developed it into a recurring motif
Structurally simpler: Failed to execute the complexity requested in the prompt
Here’s how it ended:
Lena held her hand. “It’s okay, Mom. The doctors say this is normal with your condition. The memories get mixed up.”
Aris nodded. She understood now. It was just her brain, failing. Not parallel universes. Just... entropy.
This ending violates the prompt’s core requirement: it confirms the materialist explanation and collapses the ambiguity.
With Reasoning (Same Model, Different Prompt):
Before writing a single word of the story, the model produced this extended planning phase:
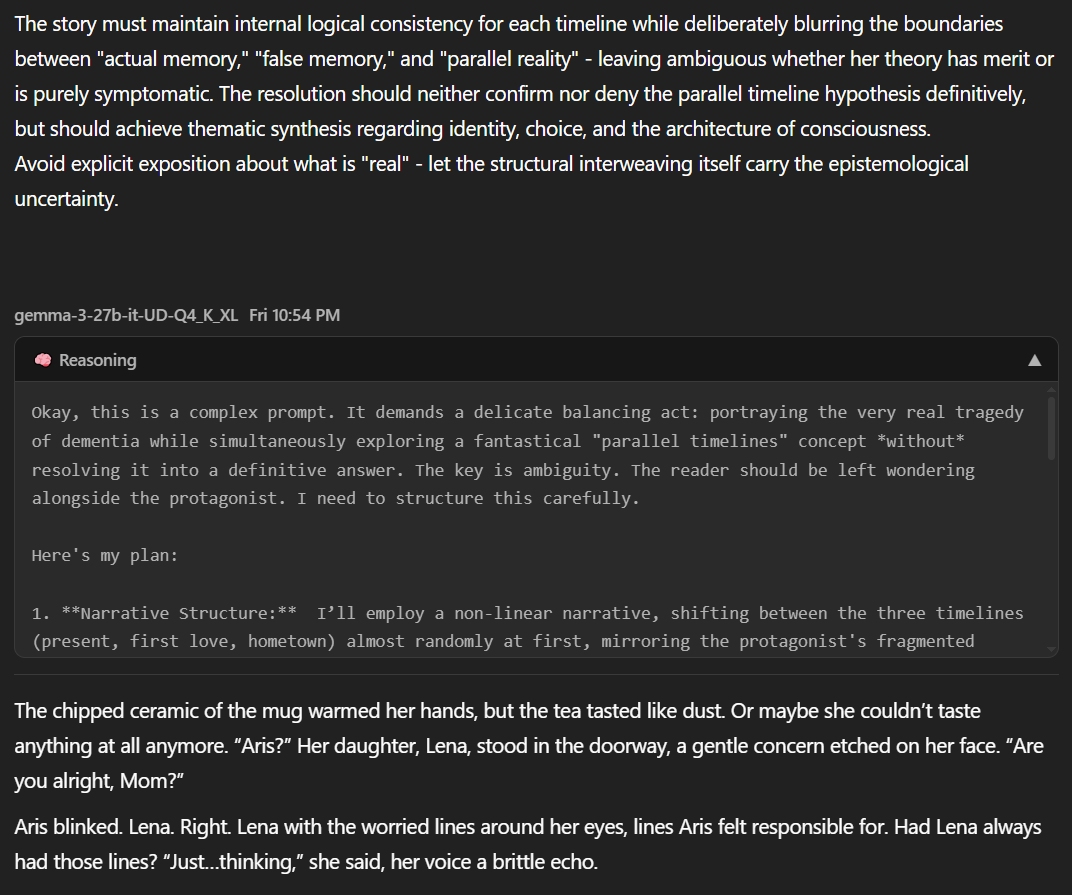
<think>
Okay, this is a complex prompt. It demands a delicate balancing act: portraying the very real tragedy of dementia while simultaneously exploring a fantastical "parallel timelines" concept *without* resolving it into a definitive answer. The key is ambiguity. The reader should be left wondering alongside the protagonist. I need to structure this carefully.
Here's my plan:
1. **Narrative Structure:** I’ll employ a non-linear narrative, shifting between the three timelines (present, first love, hometown) almost randomly at first, mirroring the protagonist's fragmented perception. The shifts will become *slightly* more structured as the story progresses, but never fully linear.
2. **Character - Dr. Aris Thorne:** A brilliant neuroscientist. This is crucial. Her expertise lends weight to her theories, even as they become increasingly…unorthodox. Her professional knowledge will subtly flavor her descriptions of her experiences, framing them in neurological terms even when she's interpreting them as timeline shifts.
3. **Timeline Differentiation:** Each timeline needs distinct emotional tones and sensory details.
* **Present:** A sense of loss, confusion, fear, and the quiet desperation of her family. Focus on sensory details that are *missing* or distorted – a scent she can’t place, a face she almost recognizes.
* **First Love (Daniel):** Warmth, nostalgia, regret, a sense of “what if.” Focus on tactile sensations – the feel of his hand in hers, the smell of his workshop.
* **Hometown (Havenwood):** A sense of stifled ambition, comfortable routine, a quiet sadness. Focus on visual details – the unchanging landscape, the familiar faces.
4. **Blurring the Lines:** This is the most important part. I need to present “memories” that are internally consistent *within* each timeline but that also feel…slippery. Details will bleed between them. A recurring object (a blue scarf, a specific flower) might appear in multiple timelines, but with slightly different significance. Dialogue will echo. The goal is to make the reader question the reliability of the narrative itself.
5. **Epistemological Uncertainty:** The ending *must not* provide a "reveal." No confirmation of parallel universes. The thematic focus should be on the subjective experience of time, memory, and identity. Aris’s peace (or lack thereof) at the end should come from accepting the ambiguity, not resolving it.
6. **Tone:** Melancholy, introspective, slightly unsettling. Avoid melodrama.
I will start with a fractured scene in the present, then immediately jump to a "memory" which may or may not be a memory, and continue to interweave throughout. Let's begin.
</think>Then it wrote the story with:
Deliberate non-linearity: Timeline shifts mirror cognitive fragmentation without becoming incoherent
The “static” motif: Appears as radio static, temporal static, “static between moments” – a polysemantic symbol developed across multiple semantic levels
Maintained ambiguity: The ending explicitly refuses resolution (”she found a fragile, unsettling peace... The resonance continued, a quiet static in the architecture of her fading consciousness”)
Distinct timeline signatures: Each reality has consistent sensory anchoring (workshop/sawdust, town square/library, hospital room/sterility)
Meta-awareness: Aris uses neuroscientific language to describe her experience, lending credibility without confirming validity
Here’s a key passage showing the structural sophistication:
“The chipped ceramic of the mug warmed her hands, but the tea tasted like dust. Or maybe she couldn’t taste anything at all anymore. ‘Aris?’ Her daughter, Lena, stood in the doorway...
[TIMELINE SHIFT - no typographical marker]
The scent of sawdust and varnish filled the air. Sunlight streamed through the workshop window... Daniel was bent over a lathe, his brow furrowed in concentration. He hadn’t noticed her yet.
[TIMELINE SHIFT - again, no warning]
The town square hadn’t changed. The same faded brick storefronts, the same chipped paint on the war memorial...”
The model seamlessly shifts between realities without explicit markers, forcing the reader to experience the disorientation. This wasn’t requested in the prompt – it emerged from the planning phase.
Here’s a longer excerpt showing how it executes this plan:
The chipped ceramic of the mug warmed her hands, but the tea tasted like dust. Or maybe she couldn’t taste anything at all anymore. “Aris?” Her daughter, Lena, stood in the doorway, a gentle concern etched on her face. “Are you alright, Mom?”
Aris blinked. Lena. Right. Lena with the worried lines around her eyes, lines Aris felt responsible for. Had Lena always had those lines? “Just…thinking,” she said, her voice a brittle echo.
“About?”
“The resonance. The temporal distortions.”
...
The scent of sawdust and varnish filled the air. Sunlight streamed through the workshop window, illuminating dust motes dancing in the golden light. Daniel was bent over a lathe, his brow furrowed in concentration...
The town square hadn’t changed. The same faded brick storefronts, the same chipped paint on the war memorial, the same Mrs. Gable gossiping on the bench outside the bakery. Havenwood. Home. A place she had sworn she would escape...
And the conclusion:
Aris looked out the window, at the grey, overcast sky. The boundaries between past, present, and possibility had dissolved. She didn’t know which timeline she was in, or if any of them truly existed. All she knew was the weight of loss, the ache of regret, and the strange, unsettling beauty of a fragmented self.
She closed her eyes, and for a moment, she wasn’t a dying neuroscientist, or a carpenter’s wife, or a small-town teacher. She was simply…a collection of echoes. And in that echo chamber, she found a fragile, unsettling peace. The resonance continued, a quiet static in the architecture of her fading consciousness. But it didn’t frighten her anymore. It simply was.
The difference is categorical. The non-reasoning version produced a structurally confused narrative that broke its own ambiguity requirement. The reasoning version executed a sophisticated multi-timeline structure with recurring symbolic motifs, maintained epistemological uncertainty, and demonstrated meta-awareness through the protagonist’s neuroscientific framing.
This isn’t incremental improvement. It’s a fundamentally different cognitive process.
The Code Test: Where It Gets Concrete
Stories are subjective. Let’s try something measurable: code generation.
Prompt: “Generate a website for a smartphone shop with HTML/CSS in 1 file”
Without Reasoning:
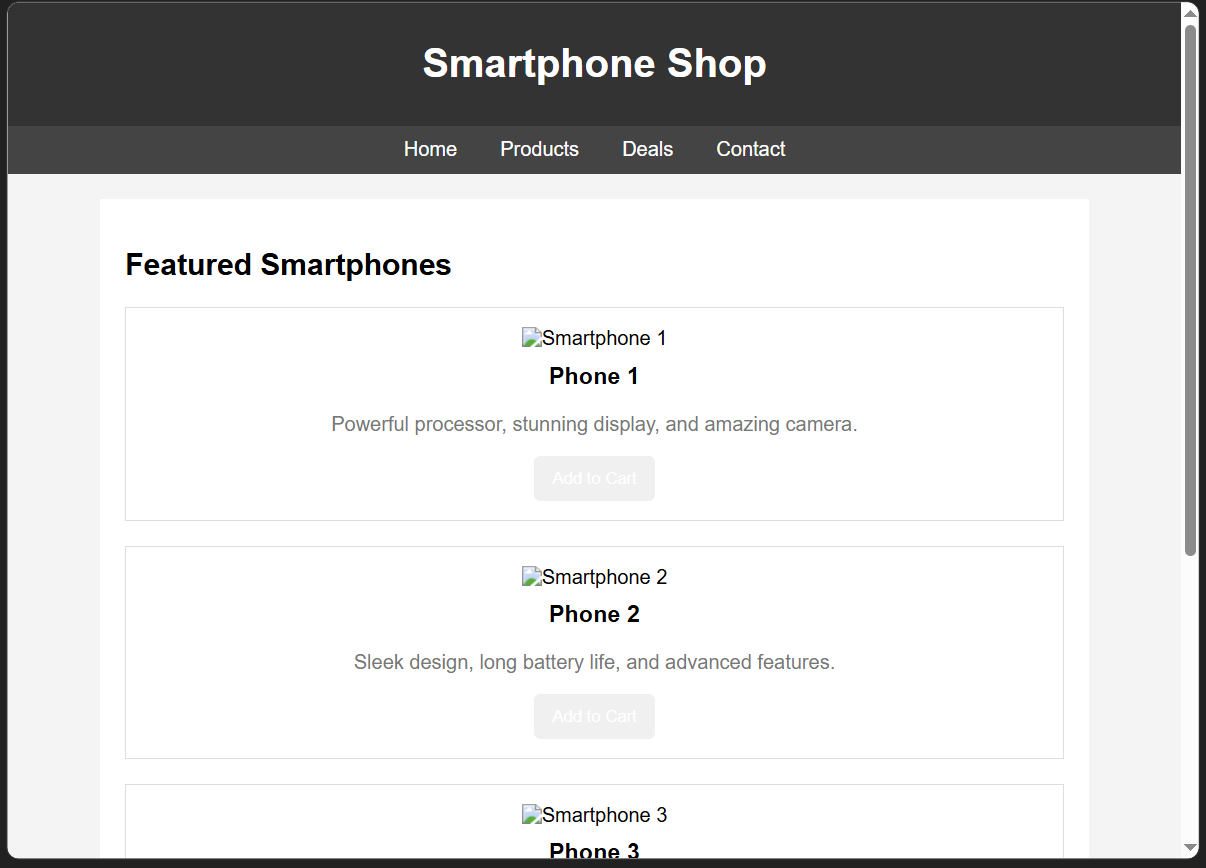
<style>
.container {
box-shadow: 1px rgba(0, , 0, 0.1); /* SYNTAX ERROR */
}
.product button {
background-color: #4CAF5; /* INCOMPLETE HEX CODE */
}
.product img {
width: 10%; /* SHOULD BE 100% */
}
footer {
bottom: ; /* EMPTY VALUE */
}
</style>Multiple syntax errors. Incomplete values. Logic mistakes. The model is generating tokens sequentially without a coherent plan.
With Reasoning:
First, the thinking:
<think>
Challenges:
- Single File Limitation: Typically websites split into multiple files.
We can't do that.
- Responsiveness: Should adapt to different screen sizes. I'll use
viewport meta tags and CSS media queries.
- Basic Styling: Needs to look presentable.
- Simplicity: Focus on header, nav, product listings, footer.
I'll prioritize clean, semantic HTML with embedded CSS. I'll use flexbox
for layout. I'll use placeholder images.
I will generate the HTML/CSS code, then provide explanation.
</think>Then it produced clean, error-free code. Here's a key excerpt showing the responsive CSS:
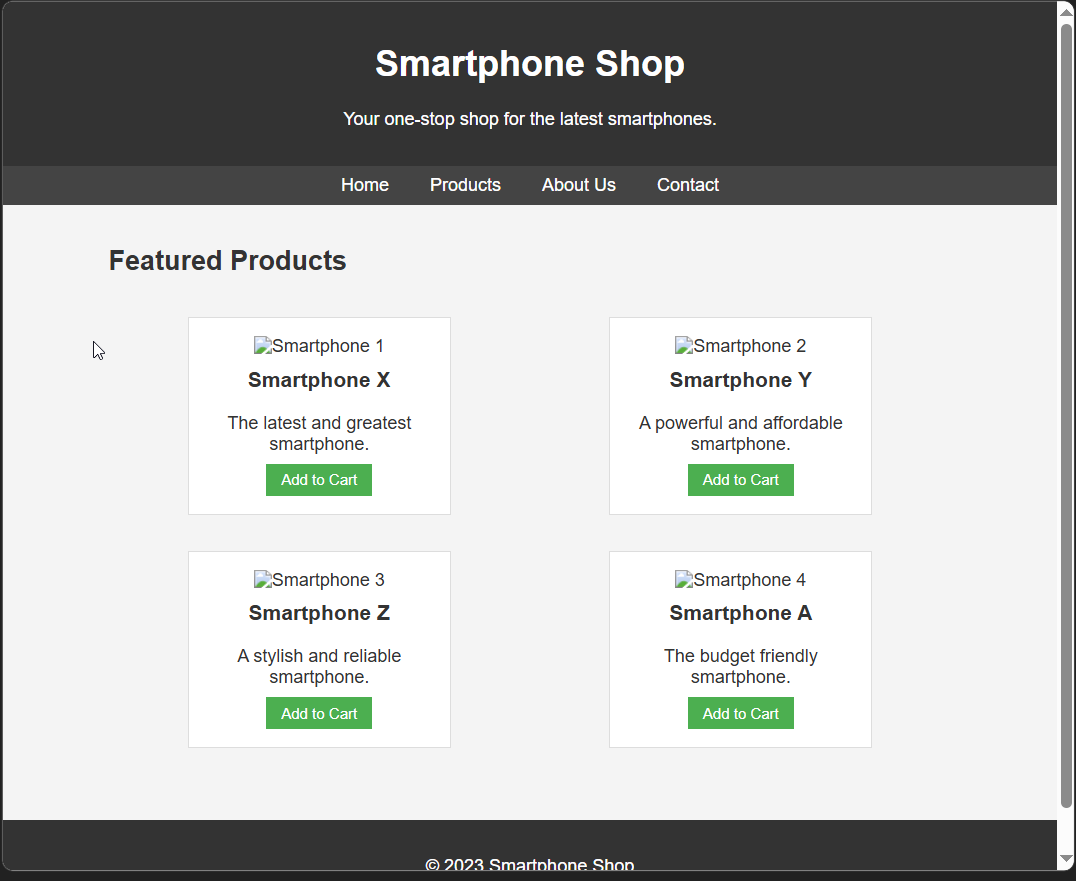
<style>
.product-list {
display: flex;
flex-wrap: wrap;
justify-content: space-around;
}
@media (max-width: 768px) {
.product { width: 45%; }
}
@media (max-width: 480px) {
.product { width: 100%; }
}
</style>Zero syntax errors. Responsive design implemented. Proper flexbox usage. Semantic HTML structure.
The difference isn’t subtle. It’s categorical.
But Here’s Where It Gets Strange
Not all models can do this.
I tested the exact same reasoning prompt on several models:
✅ Works: Gemma 3, Llama 3.1
❌ Fails: Qwen-Instruct, IBM Granite
When we tried it on Qwen-Instruct, the model completely ignored the <think> tags and either:
Fell back to
<tool_call>behavior (its strongest trained pattern)Produced incoherent output
Simply didn’t engage with the reasoning framework
This is diagnostically interesting. If reasoning-via-prompt were just about “asking nicely,” it should work for all models. But it doesn’t.
Why?
The Distillation Theory
We went digging into the technical reports. And we found something.
Gemma 3 was distilled from Gemini 2.5 Pro.
Let me repeat that: Gemma 3, a standard 27B parameter model, was trained using knowledge distillation from Gemini 2.5 Pro — which is explicitly a native reasoning model with built-in chain-of-thought capabilities.
From the Gemma 3 Technical Report:
“All Gemma 3 models are trained with knowledge distillation. Our post-training approach relies on an improved version of knowledge distillation from a large IT teacher... The exact teacher model used for distillation hasn’t been disclosed, but it’s one of the Gemini 2.0/2.5 series models.”
And from Google’s Gemini 2.5 documentation:
“Gemini 2.5 models are thinking models, capable of reasoning through their thoughts before responding, resulting in enhanced performance and improved accuracy.”
Here’s our hypothesis:
When you distill from a reasoning model, you don’t just transfer factual knowledge — you transfer cognitive strategies. The reasoning patterns are already encoded in Gemma 3’s weights. They’re just dormant.
The <think></think> tags act as an activation trigger. They’re not teaching the model to reason. They’re giving it permission to use reasoning patterns it already learned during distillation.
This would explain:
Why Gemma 3 works: Distilled from a reasoning teacher (Gemini 2.5)
Why Qwen-Instruct fails: No reasoning teacher in the lineage; their thinking models are separate post-hoc specializations
Why you need the prompt nudge: The behavior isn’t the default mode, but it’s latent in the weights
The Practical Implications
If this theory holds, it means:
Reasoning capabilities are partially transferable through distillation — even without explicit reasoning training.
You don’t need a specialized reasoning model for many tasks. You just need:
A model distilled from a reasoning teacher
The right activation prompt
A task complex enough to benefit from deliberation
This is huge for on-device AI, constrained compute environments, and anyone running local models. You might already have reasoning capabilities in models you thought were “dumb.”
How to Try This Yourself
Here’s the exact prompt we use (adapted from NousResearch’s Hermes 4.3):
You are a deep thinking AI, you may use extremely long chains of thought
to deeply consider the problem and deliberate with yourself via systematic
reasoning processes to help come to a correct solution prior to answering.
You should enclose your thoughts and internal monologue inside <think> </think>
tags, and then provide your solution or response to the problem.
<think> </think> starts at the BEGINNING, don't forget.
Important: Some models need the double-reminder about the <think> tags. They weren’t trained for this behavior, so they have no “muscle memory” for it. The repetition helps.
Test it on:
Gemma 3 (any size — 4B, 12B, 27B)
Llama 3.1 (8B, 70B)
Any model you suspect might have been distilled from a reasoning teacher
Try it on:
Complex coding tasks
Multi-step reasoning problems
Creative writing with structural requirements
Anything where planning before execution would help
What This Means for Model Development
If distillation can transfer reasoning capabilities, even partially, we need to rethink how we categorize models.
The distinction isn’t:
❌ “Reasoning models” vs. “Standard models”
It’s:
✅ “Natively reasoning” vs. “Latently reasoning” vs. “Non-reasoning”
Models with reasoning teachers in their distillation lineage occupy a middle ground. They can reason, but they need prompting to activate it.
This also raises questions about model evaluation. How many “standard” models are secretly capable of reasoning but just haven’t been prompted correctly? Are we underestimating smaller models because we’re not testing them properly?
The Limitations
This isn’t magic. Some important caveats:
1. It’s not always better For simple tasks (”What’s the capital of France?”), reasoning overhead is wasteful. The model will deliberate unnecessarily.
2. It’s slower Generating the <think> content adds tokens. This increases latency and cost.
3. It’s not guaranteed Some models simply don’t have the latent capability. Qwen-Instruct, for example, seems to require architectural changes (hence their separate thinking models).
4. It requires the right task As research shows, reasoning helps most when problems require 5+ logical steps. For simpler tasks, the benefit is marginal or even negative.
What We Still Don’t Know
This discovery raises more questions than it answers:
Is this effect limited to Gemini→Gemma distillation, or does it work with other teacher-student pairs?
Can we quantify how much reasoning capability transfers during distillation?
Do Llama 3.1 models work because Meta used similar distillation strategies?
Could we deliberately optimize distillation to maximize reasoning transfer?
We don’t have answers yet. But the fact that a simple prompt can unlock dormant reasoning in models not designed for it suggests we’re still discovering what these systems are capable of.
Try It and Tell Us
I want to know if this works for you. Specifically:
Which models work? Test the prompt on different models and report back.
What tasks benefit most? Find the sweet spot where reasoning overhead is worth it.
Can you break it? Find edge cases where it fails spectacularly.